Réponse rapide. Pour qu'une page apparaisse sur Google, celui-ci doit l'explorer puis l'indexer. Le sitemap est un fichier qui liste vos pages importantes et aide Google à les découvrir. Le robots.txt indique quelles parties ne pas explorer, mais il ne sert pas à cacher une page des résultats : pour cela, on utilise la balise noindex. Une confusion entre les deux rend souvent un site partiellement invisible.
Cet article s'adresse aux propriétaires de sites tunisiens qui veulent s'assurer que Google trouve et enregistre bien leurs pages. Il fait partie du pôle sur le SEO technique en Tunisie. Le sujet paraît abstrait, mais une erreur d'indexation peut rendre invisibles des pages parfaitement écrites.
Explorer puis indexer : deux étapes distinctes
Avant d'apparaître dans les résultats, une page passe par deux étapes. D'abord l'exploration, où Google lit son contenu. Ensuite l'indexation, où Google l'enregistre dans sa base pour pouvoir l'afficher. Une page peut être explorée sans être indexée, si Google la juge inutile, vide ou dupliquée.
Cette distinction explique beaucoup de déceptions. Un propriétaire publie une belle page, attend du trafic, et ne voit rien venir. Dans bien des cas, la page n'est tout simplement pas indexée. Vérifier ce point est la première chose à faire avant de soupçonner un problème de contenu ou de concurrence.
Le sitemap : la carte de votre site pour Google
Un sitemap est un fichier, généralement au format XML, qui liste les pages importantes de votre site. Il aide Google à les découvrir, surtout sur un site récent, volumineux, ou dont les pages sont mal reliées entre elles. Pensez-le comme une carte remise à l'explorateur.
Selon la documentation de Google, vous pouvez consulter ce qu'est un sitemap et quand en avoir besoin directement sur Search Central. Un point essentiel : le sitemap facilite l'exploration mais ne garantit rien. Lister une page n'oblige pas Google à l'indexer. C'est une aide à la découverte, pas un laissez-passer.
La plupart des sites bien construits génèrent leur sitemap automatiquement. Une fois en place, on le soumet via Google Search Console, qui signale ensuite les éventuelles erreurs.
Le robots.txt : ce qu'il fait et ce qu'il ne fait pas
Le robots.txt est un petit fichier placé à la racine du site qui indique aux robots quelles parties ne pas explorer. On l'utilise pour éviter que Google perde du temps sur des sections sans intérêt : pages d'administration, résultats de recherche interne, fichiers techniques.
L'erreur la plus répandue est de croire que le robots.txt cache une page des résultats. C'est faux. Selon Google, le robots.txt n'est pas un moyen de retirer une page des résultats. Une page bloquée à l'exploration peut quand même apparaître si d'autres sites la lient, mais sans description, car Google n'a pas pu lire son contenu.
Pour vraiment retirer une page des résultats, on utilise la balise meta noindex dans le code de la page. Et attention au piège : si vous bloquez cette page dans le robots.txt, Google ne pourra pas lire le noindex, et la page risque de rester affichée. Les deux outils ne se combinent pas, ils se choisissent.
| Outil | Ce qu'il fait | Ce qu'il ne fait pas |
|---|---|---|
| Sitemap | Aide Google à découvrir vos pages | Garantir l'indexation |
| Robots.txt | Empêche l'exploration d'une section | Cacher une page des résultats |
| Balise noindex | Retire une page des résultats | Fonctionner si la page est bloquée au robots |
Les erreurs d'indexation les plus fréquentes
Certaines erreurs reviennent sans cesse et rendent des pages invisibles sans que le propriétaire le sache. Les repérer tôt évite des mois de trafic perdu.
- Un noindex laissé par erreur : fréquent quand un site passe d'une version de test à la version publique. La balise qui bloquait l'indexation en développement reste active en production.
- Un robots.txt trop strict : une règle mal écrite peut bloquer tout le site. Une seule ligne erronée suffit.
- Du contenu dupliqué : plusieurs adresses pour la même page divisent les signaux et poussent Google à n'en indexer aucune clairement.
- Des pages orphelines : aucune page du site ne pointe vers elles, donc Google peine à les trouver. Un bon maillage interne corrige ce point.
Sur ce dernier point, le guide sur le maillage interne pour structurer son site explique comment relier vos pages pour que Google les atteigne toutes.
Soumettre un sitemap dans Search Console, pas à pas
Générer un sitemap ne suffit pas : il faut le déclarer à Google. La procédure passe par Google Search Console, l'outil officiel et gratuit. Comptez quelques minutes une fois votre site vérifié.
- Vérifiez que votre site est bien ajouté à Search Console, en propriété de domaine ou de préfixe d'URL. Cette étape prouve à Google que le site vous appartient.
- Repérez l'adresse de votre sitemap. Sur un site bien construit, elle ressemble à votre-domaine.tn/sitemap.xml. Ouvrez-la dans un navigateur pour confirmer qu'elle s'affiche.
- Dans Search Console, ouvrez le rapport Sitemaps, collez l'adresse du fichier, et validez.
- Attendez le traitement. Le rapport indique ensuite le nombre d'URL découvertes et signale les erreurs éventuelles.
- Revenez consulter ce rapport après chaque ajout important de pages.
Vous pouvez aussi déclarer votre sitemap dans le fichier robots.txt, en ajoutant une ligne qui pointe vers son adresse. Les deux méthodes se cumulent sans conflit. La marche à suivre complète est décrite dans la documentation de Google sur la construction et la soumission d'un sitemap. Un sitemap respecte une limite de 50 000 adresses et 50 mégaoctets par fichier : au-delà, on le découpe en plusieurs fichiers reliés par un index.
Le budget de crawl : guider l'effort de Google
Google ne consacre pas un temps illimité à explorer votre site. Cette enveloppe, appelée budget de crawl, dépend de la popularité de votre site, de la fraîcheur de son contenu et de la capacité de votre serveur à répondre vite. Pour un petit site tunisien, ce budget est rarement un souci. Il le devient sur un site volumineux, comme une grande boutique en ligne.
Le risque, sur un gros site, est que Google gaspille son temps sur des pages sans valeur : résultats de recherche interne, filtres de catalogue produisant des dizaines d'adresses pour le même contenu, pages techniques. Pendant ce temps, vos pages utiles attendent. La documentation de Google sur la gestion du budget de crawl des grands sites explique comment orienter l'exploration vers ce qui compte.
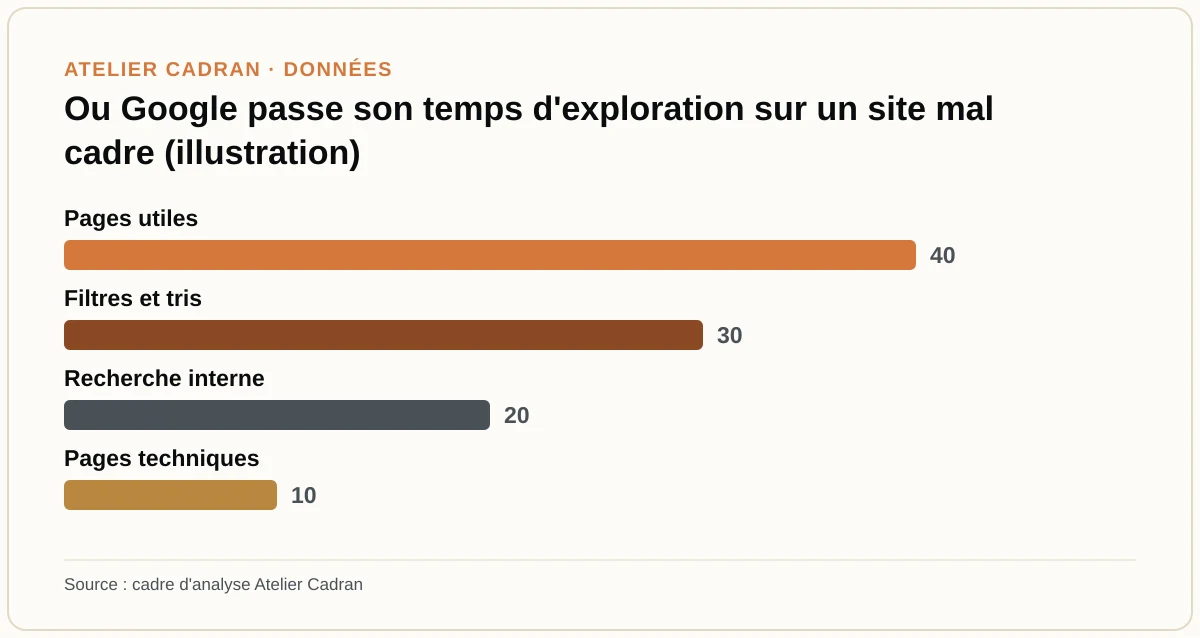
Les leviers tiennent en trois gestes. Bloquez au robots.txt les sections sans intérêt pour la recherche. Consolidez le contenu dupliqué pour éviter les adresses multiples. Et veillez à un serveur réactif, car Google ralentit son exploration si votre site répond mal. Sur un site de quelques dizaines de pages, ces réglages sont accessoires. Au-delà de quelques milliers, ils deviennent décisifs.
Vérifier et suivre dans Search Console
Google Search Console est l'outil officiel et gratuit pour suivre l'indexation. Son rapport d'indexation des pages indique combien de pages sont indexées, lesquelles ne le sont pas, et pourquoi. L'inspection d'URL permet de tester une page précise et de demander son indexation.
Prenez l'habitude de surveiller ce rapport, surtout après une refonte ou une mise en ligne. Une chute du nombre de pages indexées est un signal d'alerte à traiter vite. Pour aller plus loin sur la mesure, le guide sur les données structurées pour un site tunisien montre comment aider Google à mieux comprendre vos pages une fois indexées.
Forcer l'indexation d'une page précise
Quand une page importante n'apparaît toujours pas après plusieurs jours, vous pouvez demander à Google de la réexaminer sans attendre. La démarche passe par l'inspection d'URL dans Search Console.
- Ouvrez Search Console et collez l'adresse exacte de la page dans la barre d'inspection en haut.
- Lisez le verdict : la page est indexée, ou elle ne l'est pas avec un motif affiché.
- Si elle n'est pas indexée, vérifiez d'abord le motif : un noindex, un blocage robots, une page jugée dupliquée. Corrigez la cause avant de demander quoi que ce soit.
- Une fois la cause levée, cliquez sur Demander une indexation. Google place la page dans une file d'attente d'exploration.
Cette demande accélère la découverte, mais ne force pas l'indexation : si Google juge la page sans valeur, dupliquée ou bloquée, elle restera de côté malgré la demande. L'outil sert à signaler une page nouvelle ou récemment corrigée, pas à contourner un vrai problème de qualité ou de configuration. Réservez-le aux pages qui comptent, et ne le répétez pas en boucle sur la même adresse.
En résumé
L'indexation suit deux étapes : Google explore une page, puis décide de l'enregistrer. Une page non indexée n'apparaît sur aucune recherche, quel que soit son contenu.
Le sitemap aide Google à découvrir vos pages mais ne garantit pas leur indexation. Le robots.txt empêche l'exploration de certaines sections, sans cacher une page des résultats. Pour retirer une page, on utilise la balise noindex, jamais le robots.txt seul.
Vérifiez régulièrement votre indexation dans Search Console, soignez votre maillage interne, et méfiez-vous des noindex oubliés après une mise en ligne. Pour relier ce sujet aux autres fondations, parcourez le pôle SEO technique. Et si vous préférez confier ces réglages plutôt que de les piloter seul, découvrez comment se déroule un accompagnement en référencement naturel.